Au lycée
Trimestre 1 de NSI Terminale
Les structures de données
Un des thèmes principaux lors de l'année de terminale sont les structures de données. En toute logique, les premières structures officielles que vous avez dû traiter sont les piles et les files. Officieusement, il est toujours possible que vous ayez vu d'autres systèmes très simples et concrets (cartes, livres, fractions...), s'apparentant aux structure de données, avant les autres.
Trimestre 2 de NSI Terminale
Les structures de données
La liste chainée
Pour commencer avec les structures de données, nous allons voir une structure assez pratique : la liste chainée. En informatique, une liste chainée est une liste, où l'accés à la prochaine valeur de la liste se fait via la valeur actuelle de la liste. En effet, dans les listes normales, nous pouvons accéder directement à chaque élément (stockés 1 à 1 dans la mémoire).
Dans une liste chainée, le prochain élément peut se trouver n'importe où dans la mémoire, et le seul moyen d'y accéder est un lien vers le prochain élément. Ici, ce lien est nommé un pointeur. La représentation habituelle de cette structure est un ensemble de valeurs, liées entre elles par des liens (d'où le nom : liste chainée).
Pour pouvoir distinguer l'élément, nous allons utiliser le pointeur. En effet, nous allons définir le dernier élément comme un élément tel qu'il n'y en a pas d'autres après. Donc, cet élément ne doit pointer vers rien du tout. En informatique, un pointeur ne pointant vers rien est nommé un pointeur vide, et le pointeur du dernier élément d'une liste chainée est donc un pointeur vide. En Python, nous disons que ce pointeur est de valeur "None".
Ce type de liste a donc pas mal de caractéristiques. Chaque élément doit donc représenter deux variables (au moins) : sa valeur et le prochain pointeur. Donc, insérer un élément à la liste revient à changer le pointeur de l'élément d'avant vers le nouvel élément, et mettre le pointeur du nouvel élément vers le prochain élément (ou vide si il est le dernier élément).

En toute logique, la suppression d'un élément revient à supprimer le pointeur qui pointe vers lui, pour pointer vers l'élément suivant. L'accés à un élément doit se faire en passant du premier élément jusqu'à l'élément souhaité (de même pour la mesure de la taille). De plus, un élément d'une liste chainée peut représenter une sous-liste chainée de la liste de départ (bien évidemment, que si elle a un enfant). Donc, cette struture peut se représenter de manière totalement récursive.
Beaucoup d'implémentations Python sont possibles. Pour en citer quelques unes : avec des éléments sous forme de tuple, de liste, de dictionnaire... En général, celle utilisée en priorité est l'implémentation via une classe. L'idée est de créer une classe, représentant un élémént, contenant un pointeur vers le prochain élément et la valeur de l'élément actuel. Voici un petit exemple d'implémentation :
"""Classe représentant une liste chainée (et donc, un élément de liste chainée)"""
def __init__(self, valeur, prochain = None):
"""Constructeur de la classe"""
self.valeur = valeur
self.prochain = prochain
def prochain(self):
"""Retourne la valeur de l'élément"""
return self.prochain
def valeur(self):
"""Retourne la valeur de l'élément"""
return self.valeur
Pleins d'autres méthodes sont possibles, selon ce qui est demandé.
L'arbre de données
Maintenant que nous avons vu les listes chainées, nous allons voir une structure utilisant le même concept de manière légèrement différente : l'arbre. En informatique, un arbre de données représente une structure de données où chaque élément permet d'accéder aux prochains éléments (en sachant qu'ils peuvent être plusieurs). La seule différence avec la liste chainée est que un élément d'une liste chainée ne pointer que vers un seul autre élément (le prochaine), là où un élément d'un arbre peut pointer vers plusieurs (ou aucun) éléments. Le nom arbre vient de la représentation la plus célèbre de cette structure : un arbre inversé.
De manière assez logique, cette structure partage pas mal de points communs avec la liste chainée. Dans un arbre, un élément représente lui même un arbre. L'ajout d'un élément demande d'ajouter un pointeur vers cette élément, le retrait d'un élément demande d'effacer le pointeur... Cette structure a pas mal d'utilisation en informatique : page web (les balises forment un arbre), le référencement web... Cependant, le vocabulaire utilisé est légèrement différent. En effet, les sous-arbres peuvent être appelés noeuds (ou branche), les derniers éléments sont appelé feuilles, le premier est appelé racine, le nombre total de données est appelé taille, et le nombre maximal de chemins entre la racine et les feuilles est appelé hauteur de l'arbre. Comme pour les autres structures, des milliers d'implémentations sont possible, dont voici un exemple :
"""Classe représentant un arbre (et donc, un élément d'arbre), avec une liste de pointeurs pour les enfants"""
def __init__(self, valeur, enfants = []):
"""Constructeur de la classe"""
self.valeur = valeur
self.enfants = enfants
def enfants(self):
"""Retourne les enfants de l'élément"""
return self.enfants
def valeur(self):
"""Retourne la valeur de l'élément"""
return self.valeur
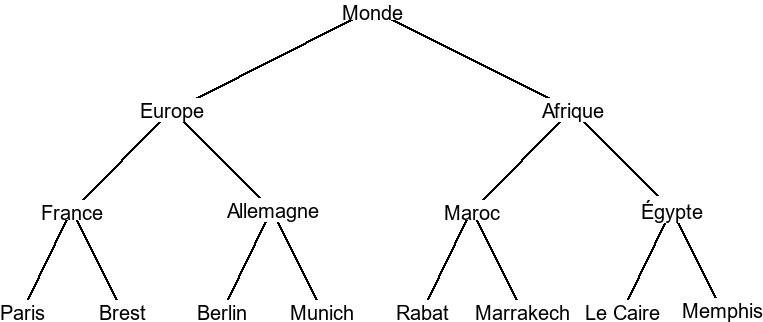
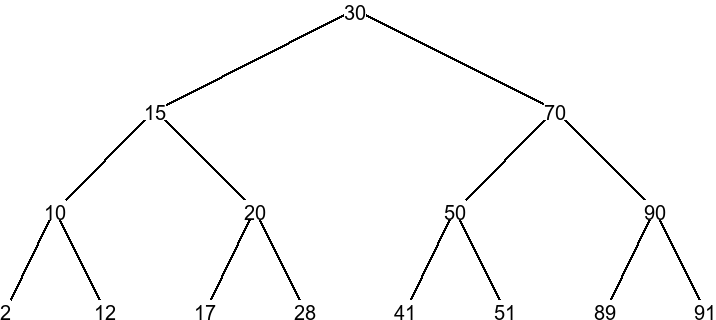
Certains arbres possèdent des propriétés spéciales, étudiées en terminale. Le plus célèbre est l'arbre binaire. Un arbre est binaire si chacun de ses noeuds / branches à au plus 2 sous-arbres(c'est le cas pour l'abre "Monde" plus haut). Il est souvent utile de distinguer ces deux sous-arbres, qu'on appelle sous-arbre gauche et sous-arbre droit. Cette propriété permet d'en définir pas mals d'autres assez simple, comme la formule de la taille t maximale d'un arbre de hauteur n :
Cette formule se déduit facilement avec quelques connaissances basiques en suites mathématiques (vues en seconde et en première). Grâce à ces arbres binaires, on peut créer d'autres types d'arbres. Ici, nous allons parler de l'arbre binaire de recherche. Un arbre binaire de recherche est un arbre binaire adapté pour ranger (trier et chercher) des données. Son fonctionnement est assez simple : chaque noeud contient une donnée, et toutes les données de son sous-arbre gauche sont inférieures à lui, et les données de son sous-arbre droit sont supérieures à lui. Cet arbre permet d'implémenter des algortihmes de recherche particulièrement efficaces.

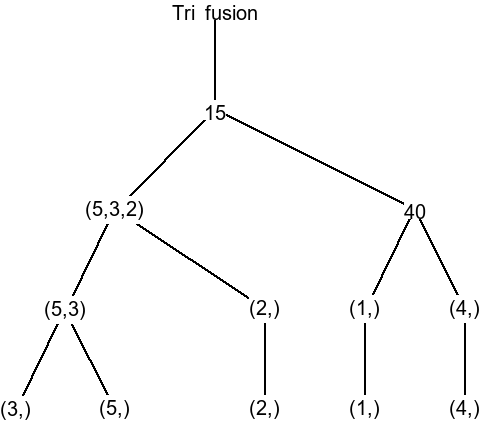
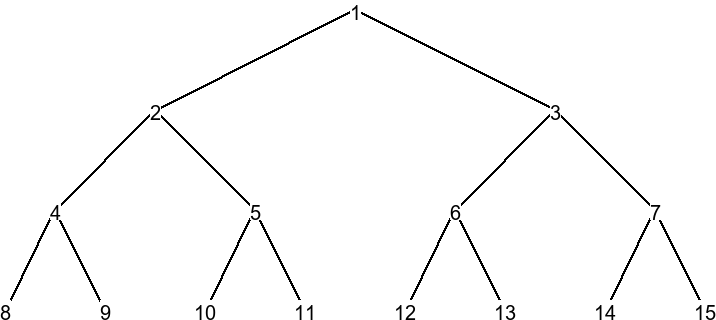
En parlant d'algorithmes de recherche, il est aussi à noter que ceci sont abordés pour les arbres binaires. En effet, 4 algorithmes de parcours sont vus : le parcours préfixe, infixe, suffixe et en largeur. Le parcours préfixe consiste à regarder dans cet ordre précis : la valeur de la racine d'un arbre, puis le sous arbre gauche (via récursion), puis le sous arbre droit (via récursion). Le parcours infixe change cet ordre : on regarde le sous arbre gauche (via récursion), puis la valeur de la racine, puis le sous arbre droit (via récursion). Finalement, le parcours suffixe change (encore) l'ordre : on regarde le sous arbre gauche (via récursion), puis le sous arbre droit (via récursion), puis la valeur de la racine. Le parcours en largeur est un peu plus original : on regarde la valeur de la racine d'un arbre, puis celle de tous les sous-arbres (que la racine), puis celle des sous-sous-arbres... L'algorithme le plus efficace dépend grandement du contexte, bien que le parcours préfixe soit généralement le plus utilisé. Voici un exemple de comment les noeuds sont parcourus pour un parcours en largeur.
Comme pour toutes les structures de données ici : ce qui est vu ici est abstrait. Théoriquement, tout ce qui contient, de prés ou de loin, une valeur et un pointeur vers la prochaine valeur peut être appelé une liste chainée. De plus, tout ce qui contient, de prés ou de loin, une valeur et des pointeurs vers plusieurs autres valeurs peut être appelé un arbre. L'idée ici est (comme pour le premier trimestre) de donner aux élèves une nouvelle façon possible de structurer des données, ici de manière chainée.
Les systèmes d'exploitation
Les tâches et processus
Le fonctionnement global d'un système d'exploitation est abordé au programme de terminale. En informatique, une tâche représente l'ensemble du néccessaire pour faire faire quelque chose à l'ordinateur. Sur Internet, il est difficile de trouver une définition précise et acceptée par tout le monde : une tâche peut représenter (selon le système utilisé) un fil d'exécution, une action brute, une action complète... Un terme mieux définit est le terme de processus. En effet, un processus représente un ensemble de tâches permettant le déroulement d'un programme, et les ressources allouées. Par exemple, ouvrir un logiciel revient à créer un (ou plusieurs) processus : ceux qui permettent de faire marche le logiciel.
Dans un ordinateur, plusieurs logiciels peuvent tourner en même temps. En effet, le système d'exploitation se débrouille pour exécuter tous les processus de manière quasi-simultanée. Or, qu'une partie limité d'un processus peuvent avoir lieu à la fois. Pour créer l'illusion de simultanéité, le système d'exploitation va pouvoir exécuter une partie d'un processus, puis une partie d'un autre processus...Grâce à la grande vitesse des ordinateurs modernes, une illusion de simultanéité est crée. Le fait de ranger les processus dans un ordre permettant de les exécuter un à un est nommé l'ordonnancement(ou scheduler en anglais). Or, cela implique que, à un moment précis, un processus peut : soit attendre d'être exécuté, soit attendre une signal permettant de le mettre sur liste d'attente pour l'exécution, soit être exécuté, soit être fini. Ces états, respectivement "prêt", "endormi", "élu" et "terminé" sont nommés états de processus. Ils permettent à l'ordonnanceur de proprement trier les processus.
Les techniques utilisées par l'ordonnanceur pour gérer les processus sont aussi étudiés en terminale. Déjà, nous allons introduire la possibilité de représenter un processus comme un ensemble (fini, et dont on connait la taille) de tâches plus petite, et définir le moment où le processus est élu comme l'exécution d'une de ses tâches. Dans ce cas, nous allons simplement classer les tâches à trier dans l'ordre nécessaire. Pour cela, plusieurs algorithmes sont possibles. Le premier consite à les enfiler un à un par ordre d'arrivé. Il est extrêmement simple à comprendre, mais ne permet pas vraiment de donner l'impression de quasi-simultanéité de l'ordinateur (si vous lancez un logiciel, il faudrait attendre que tous les autres se ferme pour l'utiliser). Le deuxième, assez similaire, consiste à trier les processus du plus long au moins long. Dans ce cas, le tri à lieu à chaque fois qu'un nouveau processus est lancé (il est inséré après un processus plus long et avant un processus moins long). Il présente le même problème que l'algorithme d'avant : quasi-simultanéité inexistante. Finalement, le dernier algorithme consiste à exécuter une tâche d'un processus, puis d'un autre processus... Après avoir exécuter une tâche de tous les processus, on recommence. Cet algorithme est nommé le tourniquet.
L'idée ici est de comprendre les bases du système d'attribution de ressources dans un ordinateur. Bien évidemment, ce n'est qu'une base, mais elle est quand même importante pour comprendre le fonctionnement global d'un système. Elle permet aussi l'introduction au multitâche, utile pour les systèmes de multithreads, très utilisés en programmation.
Linux
Tout ceux qui font de l'informatique le savent : le système d'exploitation préféré des développeurs est Linux. Cela tombe bien : les bases de Linux sont abordées dans le programme de terminale NSI. Pour rappel : Linux est un noyau de système d'exploitation (nommé dans le jargon un kernel), qui est la base de beaucoups de systèmes d'exploitations, nommés des distributions Linux : Ubuntu, Debian, Mint... Il est basé sur une norme très précise de systèmes d'exploitation : UNIX(qui, lui même, est basé sur d'autres normes : POSIX). UNIX a été développé au début des années 70 (avec pleins de versions par ci, par là), par pas mal de personnes, dont Ken Thompson et Dennis Ritchie (l'inventeur du langage C, crée pour UNIX en 1972). En 1977, une version plus complète d'UNIX, nommée BSD est publiée par AT&T (l'ancêtre des systèmes modernes FreeBSD ou OpenBSD). En 1983, Richard Stallman trouve la licence d'UNIX trop privative, et décide de développer une version plus libre : GNU. D'ailleurs, avec ce système, le nom "UNIX" devient plus un ensemble de normes qu'un système d'exploitation. En 1991, Linus Torvald crée un noyau de système d'exploitation particulièrement adapté aux serveurs : Linux. Au fil du temps, toutes les versions de Linux apparaîtront elles aussi (Debian en 1993 par Ian Murdock, Ubuntu en 2004 par Mark Shuttleworth...), pour rendre le système facilement utiliasble par le grand public. Cependant, des systèmes d'exploitations non-libres respectent aussi les normes UNIX : Windows NT par Microsoft, ou même MacOS par Apple.
L'avantage de Windows est qu'il respecte les normes UNIX. Donc, les normes de Windows ne sont pas bien différentes des normes UNIX. Ces normes incluent le système de processus vu plus haut. Mais aussi, elles incluent la possibilité de gérer les fichiers sous forme d'arborescence, et de chemin d'accés (chemin vers un fichier). Sur Linux, l'arborescence respecte des normes particulièrement précises.

Lors de la création d'UNIX, le contrôle de l'ordinateur se faisait par un système de commande. En effet, pour interagir avec l'ordinateur, il n'y avait qu'une zone de texte, dans laquelle on pouvait noter les actions que doivent faire l'ordinateurs, nommées des commandes. Ce système existe toujours de nos jours (sur Linux, ou même Windows et MacOS), bien qu'il ne soit pas le plus utilisé (l'interface graphique reste plus efficace, sauf dans certains cas précis, comme pour des serveurs à distance). Il permet aussi de faire de l'édition de fichiers textes directement dans cette zone de texte (bien que ce ne soit pas extrêmement pratique). Plusieurs programmes différents existent pour cela, comme nano ou vim. En parlant de programme, l'exécution d'un programme via ces commandes se fait en appellant directement le programme (via son chemin d'accés) en tant que commande. Cependant, pour les cas où les commandes sont nécessaires, il faut connaître les commandes basiques de Linux. Pour commencer, il faut savoir que l'endroit où l'on tape les commandes (et où les réponses sont affichées) est nommé le terminal (CLI ou shell en anglais). À chaque instant, le terminal va travailler dans un dossier précis de l'arborescence, nommé répertoire actuel. Si vous créez un fichier, il sera crée dans le répertoire actuel. Ces mêmes commandes ont toutes un nom précis, et aussi des paramètres possibles (qui peuvent d'ailleurs être vide). En plus, elles peuvent aussi comporter des options spéciales, qui sont facilement reconnaissable, car on les écrit avec un "-" devant. À partir de là, vous pouvez comprendre toutes les commandes basiques, exposées dans un tableau.

En tout, il y a plus d'un millier de commandes sur Linux, tout personnalible à souhait. Le principal est de connaître les commandes basiques, et leur syntaxe. En plus, il existe un langage de programmation qui consiste entièrement en des commandes de ce genre : Bash. Il permet d'automatiser l'exécution d'une grande quantité de commandes similaires.
En informatique, connaître Linux est toujours un plus. Il est plus simple pour le développement informatique, tout en restant très accessible. Cependant, comme il n'est pas extrêmement utilisé, il pêche sur certains domaines, comme le multimédia ou le jeu vidéo. Donc, n'hésitez pas à aller y jeter un coup d'oeil si ce système pourrait vous intéresser.
Réseau et routage
Finissons ce trimestre en beauté, avec du réseau. Cette partie sur le réseau est la suite logique de la partie vue en première. Pour rappel du premier trimestre, une IP (pour Internet Protocol) représente une adresse d'une machine sur un réseau. Ce même réseau peut être constitué de toute sorte de machine : ordinateur, tablette, téléphone... Pour transiter, une information circule sous forme de requête, découpée par petit morceau dans ce que l'on appelle des paquets. Certaines machines permettent de diriger précisément les requêtes : ce sont des routeurs. Tout cela représente le nécessaire pour voir les choses vues en terminale.
Pour commencer, il faut savoir que la notion d'adresse IP est très approfondie en terminale. Déjà, une IP n'est valable que dans un seul réseau, et une même machine peut avoir plusieurs IPs dans plusieurs réseaux différents. Cette même IP est distribuée par le fournisseur du réseau (qui, en tout logique, s'occupe aussi du routage). D'ailleurs, le réseau entier à lui aussi une IP un peu spéciale. En effet, toutes les IPs du réseaux partagent un même début (permettant d'identifier le réseau auquel elle appartient), que l'on peut obtenir avec ce que l'on appelle le masque de réseau. Ce masque de réseau contient une IP précise. Pour bien le comprendre, rappellons nous qu'une IP correspond à un nombre, comme 145.68.168.32. On peut représenter cette IP sous-forme binaire : 10010001.01000100.10101000.00100000. Dans ce cas, une IP masque est une IP où tous les premiers chiffres sont des 1, puis que des 0. Par exemple, 255.255.240.0 (ou 11111111.11111111.11110000.00000000) peut être une IP masque. À partir de là, nous pouvons obtenir l'IP du réseau, en obtenant l'IP tel que, pour chaque 1 de cette IP, l'IP d'une machine et l'IP du masque est 1, sinon le nombre est 0. Cette opération est une opération binaire, nommée ET (1 ET 1 = 1, 1 ET 0 = 0, 0 ET 1 = 0, 0 ET 0 = 0). Dans notre cas, nous pouvons facilement obtenir l'IP du réseau.

Vous avez donc l'IP de réseau 145.68.160.0. Pour indiquer simplement le masque dans une adresse IP quelconque, il existe une notation assez simple : la notation CIDR. La notation CIDR consiste à rajouter un nombre après l'IP, qui représente le nombre de 1 dans le masque de réseau. Dans le cas vu plus haut, l'adresse IP CIDR de notre machine serait 145.68.168.32/20.
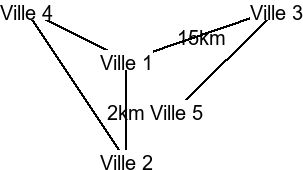
Avec ce système d'IP, le routage est possible via des routeurs. En terminale, deux algorithmes de routages sont étudiés. Le premier est le plus simple et le plus intuitif : RIP (pour Routing Information Protocol). Le protocole RIP consiste à connaître tous les sous-réseaux disponibles dans le réseau, et à lui envoyer la requete directement. Ce protocole implique de connaître tous les sous-réseaux du réseaux, et donc de les stocker en mémoire (et de l'actualiser souvent en cas de panne). De plus, les sous-réseaux doivent être particulièrement bien ordonnés, pour ne pas qu'un routeur n'est à stocker trop d'autres routeurs en une fois. Pour être précis, le routeur va aussi stocker le nombre de routeur le séparant de chaque sous-réseau, ainsi que le premier routeur du chemin allant à chaque sous-réseau. Donc, ce protocole permet d'avoir une idée de la distance entre un routeur de départ et un routeur cible (bien que cette façon de faire n'est pas la plus optimisée). Voici un exemple de réseau, et la façon dont le routeur 128.34.0.0 traiterait les informations selon ce protocole.


Le prochain protocole est un protocole bien plus rapide, mais un peu plus complexe. Il s'agit du protocole OSPF (Open Shortest Path First). Le protocole OSPF consiste aussi à connaître tous les sous-réseaux disponibles dans le réseau, et à lui envoyer la requete directement. Il est très similaire au protocole RIP, mais il a quand même une différence. Cette différence ce joue sur la manière dont le protocole calcul la distance entre deux routeurs. En effet, là où le protocole RIP calcul le nombre de routeurs entre l'envoyeur et la cible, le protocole OSPF prend en compte la vitesse de chaque routeurs (et de chaque connection entre deux routeurs). Par exemple, un câble fibre est bien plus rapide qu'un câble ADSL, et sera considéré comme moins long à parcourir par le protocole OSPF. Pour être précis, le choix va se faire par rapport à une valeur précise, nommée le coût de la connection. Ce coût se calcule en divisant 100 millions par le nombre de bits transférables par seconde (aussi nommé la bande passante de la connection). Cependant, dans certains sujets de BAC, ce n'est pas 100 millions mais une autre valeur quelconque. Par exemple, une connection à 1 Gb / seconde aura un côut de 0.1, et une connection à 10 Mb / secondes aura un côut de 10. Grâce à ça, le transfert d'information est beaucoup plus rapide.
Avec cette partie, nous entrons dans les bases de l'administration réseau, pour donner un avant goût de comment configurer un réseau. C'est une partie qui devrait plaire à tous les gens aimant bien cette partie.